
In this picture, the money values are at most £100. That's merely to narrow the cells so I can squeeze this picture into the Dobbs blog column width:
I'm posting this article to show how I believe spreadsheets should be coded: write the documentation first, and describe every cell group in pseudo-code. Then translate into Excel. No more undocumented cell groups; no more mysterious formulae: a boon to you and everyone who will maintain your spreadsheet.
Pseudo-code is notation that looks like a programming language, but that is not executable. It's an idea that has been around computer science since at least the 1960s: Wikipedia claims that it started with the programming language Algol. But if it isn't executable, why bother with it? Because, like mathematical notation, it is less cumbersome and more precise than English.
You can see this by looking at some examples from Bob Roggio. By using if-then-else statements and loops to describe algorithms, they avoid ambiguities such as (in instructions for the use of shampoo) "Wash hair, rinse, and repeat." In that sentence, it isn't clear whether the "repeat" applies to both the washing and the rinsing, or only to the rinsing.
The pseudo-code I describe here is my own design, rather different from those examples, but its purpose is the same. Also, it simplifies the job of writing, by giving you a fixed pattern to follow, so you need to make fewer writerly decisions.
Rather than explain further, I'll jump straight into an example. It's a loans spreadsheet, a rational reconstruction of part of an Excel project-planner written by one of my customers. Do note that I've simplified it in order to demonstrate principles, so it would need enhancement for real-world use. The loans, for example, don't have interest or monthly repayments. But it will show how you should document a spreadsheet.
I want you to think in terms of "tables". By this, I don't mean pivot tables or anything else that Excel calls a table: I merely mean groups of logically related cells. Eventually, we'll map these into specific locations on worksheets, but when writing the documentation, I want you to regard as things in their own right.
When we think of a table, we must think of a name by which our documentation will refer to it. We must tell the reader how big it's going to be. We must also tell the reader what its purpose is, and make it clear exactly what it contains: how each cell relates to other cells, to the time during which it holds, and so on. THIS IS IMPORTANT, BUT OFTEN NEGLECTED IN DOCUMENTATION! And we must state the equations that define how to calculate the tables' elements.
To do these things, I shall use the following stylised documentation elements. Firstly, table definitions. These resemble the way one specifies functions in mathematics, and have the form:
table table name : bounds -> result type.for example:
table total_cash_at_start_of_period : time_span -> currency.
The table name should clearly indicate the table's purpose. If the name contains more than one word, separate them by underlines, and choose the words so they make a meaningful phrase.
The result type describes the kind of data each cell holds, and can be one of the cell-contents categories that Excel displays on the Number tab of its Format Cells dialogue: a name such as "general", "number", "currency" or "date". We shall see later that I also use the name "boolean", for cells that contain the logical values true or false.
The bounds specify the size of the table, and should be a name defined in the second kind of documentation element, a bounds definition. A bounds definition takes the form:
bounds bounds name: low bound to high bound.For example:
bounds time_span: 1 to 12.
My reason for naming the bounds is that several tables may share the same bounds. In this cash-flow forecaster, for example, almost all the tables range over the same time span. Using a single name means you can define it in one place in the documentation, and easily update this when necessary.
The third kind of documentation element is an equation. This takes the form:
left-hand side =For example:
right-hand side.
total_cash_at_end_of_period[ t ] =
total_cash_at_start_of_period[ t ] - expenses_during_period[ t ].
The right-hand side is an Excel formula, but with cell names replaced by table elements. Write table elements like array elements in a conventional programming language, with the table name followed by square brackets enclosing one or more indices.
The left-hand side is a table element where each index is: a constant; an "any value" variable; or an "any value" variable with a comparison that restricts its values. For example:
total_cash_at_end_of_period[ 1 ]
total_cash_at_end_of_period[ t ]
total_cash_at_end_of_period[ t > 1 ]
Finally, the fourth kind of documentation element is like a "comment" in a conventional programming language. It gives extra information about the purpose and content of a table, whenever the documentation elements above are not enough on their own. A comment consists of two dashes followed by English text, which will usually refer to one or more tables, table elements, or bounds. The dashes are to alert the reader quickly that it isn't one of the first three kinds of documentation element. For example:
-- total_cash_at_start_of_period[t] is the total cash
held at the beginning of the first day of period t.
If you write documentation in this way, you will automatically end up with a description of almost every cell in your spreadsheet. How nice for the people who will maintain it!
The only cells you may not find yourself documenting are captions and other static text. Which is fine, because their purpose will normally be self-evident. But, if anything particularly unusual is required of these, you should document that too. For example, if certain labels need to be in merged cells, or in capitals, or intelligible to a user who doesn't know the jargon of your trade.
Now I'll proceed with the spreadsheet, starting with the easiest part, the cash-flow tables. We shall forecast cash flow over monthly periods, displaying two tables. One shows total cash at the start of each period; one, total cash at the end of each period.
It's the recession, so let's assume there's no income, only expenses. Then total cash at the end of each period equals total cash at the start of each period minus expenses during the period. We can write this mathematically as:
total_cash_at_end_of_period(t) =
total_cash_at_start_of_period(t) + expenses_during_period(t).
Here, I'm viewing total_cash_at_end_of_period, total_cash_at_start_of_period and expenses_during_period as functions that map a period indicator t to money. It doesn't matter what t is as long as it uniquely identifies periods. For example, it could be an integer index, with 1 meaning 1st January 2009 to 31st January 2009, 2 meaning 1st February 2009 to 28th February 2009, and so on.
Now let's document this according to the above principles. I shall make total_cash_at_end_of_period, total_cash_at_start_of_period, and expenses_during_period into tables. I need to add an initial_cash table to give a starting value for total_cash_at_start_of_period. And I'm going to add a "time" table which shows the first date of each month. I shan't need this for my calculations, but will use it in captions.
I shall also need equations. One, for total_cash_at_end_of_period, will be very similar to the function above. But let's look at the whole lot:
bounds time_span: 1 to 12.
table time : time_span -> date.
-- time[t] is the date of the first day of
period t. The final day of period t is
the final day of its month, which is
calculated below.
time[t] = date( 2009, t, 1 ).
table initial_cash : -> currency.
-- initial_cash[] is the "opening cash balance",
the value for the first period's total_cash_at_start_of_period.
This will be input by the user.
table expenses_during_period : time_span -> currency.
-- expenses_during_period[t] is the expenses incurred during
period t: during the first day to the final day inclusive.
This will be input by the user.
table total_cash_at_start_of_period : time_span -> currency.
table total_cash_at_end_of_period : time_span -> currency.
-- total_cash_at_start_of_period[t] is the total cash
held at the beginning of the first day of period t.
Similarly, total_cash_at_end_of_period[t] is the total cash
held at the end of the final day of period t.
total_cash_at_start_of_period[ 1 ] =
initial_cash[].
total_cash_at_start_of_period[ t>1 ] =
total_cash_at_end_of_period[ t-1 ].
total_cash_at_end_of_period[ t ] =
total_cash_at_start_of_period[ t ] - expenses_during_period[ t ].
Notice how careful I've been to say explicitly how the tables relate to the time periods. This is important! How many of us have coded half a cash-flow forecaster, only to discover an off-by-one error in our indexing, with the effect that — for example — cash for month m equals cash for month m minus expenses for month m. To which the only solution is that cash be either infinity or minus infinity: neither physically possible, even if the latter often feels as though it is.
Now, this is a very simple specification,
but it's still good to test it.
So I've translated it into
Excel. Tables, as I said are just
groups of cells, and I've arranged these in
columns, each headed by its name. You can download
the resulting
spreadsheet
here.
This is
a picture of it:
In this picture, the money values
are at most £100. That's merely to
narrow the cells so I can squeeze
this picture into the Dobbs blog column width:
By the way, I tucked the "time" table out of the way on a sheet called Time. Whenever I want to use the dates in it as captions, I copy them. This separates how captions are calculated from how they are displayed. As Phil Bewig points out in his paper How do you know your spreadsheet is right? Principles, Techniques and Practice of Spreadsheet Style, separating calculation from display is a Good Thing.
I'm now going to add loans to my spreadsheet. As before, I'll document this first, and only then translate the documentation into a spreadsheet. As a first step, I shall incorporate a borrowing term into the total_cash_at_end_of_period equation:
total_cash_at_end_of_period[ t ] =
total_cash_at_start_of_period[ t ] - expenses_during_period[ t ] +
actually_borrowed_during_period[ t ].
I'll also define two more tables. Into one of them, the user types the amount they want to borrow in any period. The other, actually_borrowed_during_period, will hold the amount the loans allow them to borrow. In this first-step version, I'll make the two equal:
table want_to_borrow_during_period : time_span -> currency.Note that, once again, I have specified each table in pseudo-code, and also stated precisely what each cell in it means.
-- want_to_borrow_during_period[t] is the amount
the user wants to borrow during period t.
table actually_borrowed_during_period : time_span -> currency.
-- actually_borrowed_during_period[t] is the amount
the loans enable the user to borrow, taking
borrowing limits into account. This will be less than
or equal to want_to_borrow_during_period[t].
actually_borrowed_during_period[ t ] =
want_to_borrow_during_period[ t ].
I'll now translate this into a spreadsheet.
In the image below, you can see I've typed amounts of
�20 and �10 into want_to_borrow_during_period.
Please notice that these
are mirrored in actually_borrowed_during_period:
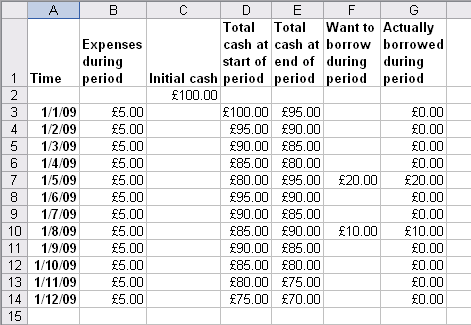
By the way, I reduced the dates to DD/MM/YY format
so that the image fits the blog column width.
Now, I'll add the loans stuff and change how actually_borrowed_during_period depends on want_to_borrow_during_period. Firstly, because I no longer want them to be equal, I remove that equation I added:
actually_borrowed_during_period[ t ] =.
want_to_borrow_during_period[ t ]
And secondly, I implement the loans. We shall have a fixed number of these. Each loan is like a credit card: you can borrow at any time, as long as the total you have borrowed doesn't exceed a ceiling. In the spreadsheet that inspired mine, there was also a "catch-all" loan with no ceiling: you could, in theory, borrow an infinite amount. I'll allow such loans too. So we need to define the number of loans, the ceilings of those that have ceilings, and a flag to say which do and which don't:
bounds loans_span: 1 to 4.
-- This gives the number of loans.
table has_ceiling : loans_span -> boolean.
has_ceiling[l] is true if loan l has a ceiling.
table ceiling : loans_span -> currency.
-- ceiling[l] is l's ceiling. That is, the user can borrow
any amount B such that B ≤ ceiling[l]. If
not( has_ceiling[l] ), the user can borrow without limit.
Do you see how I made has_ceiling distinct from the ceiling? I prefer this over a "nonsense value" convention such as that if a ceiling is -1 or #N/A, then it is infinite. Spreadsheeters often do rely on such nonsense values, but using a separate group of cells produces code that's easier to read and modify.
Now that I've described the parameters defining a loan, I shall model the loans' progress through time. First, I need an initial value, because the loans could have been arranged and borrowed from before the first cash-flow period. So I shall make a table analogous to initial_cash. Actually, you'll have seen it in the picture above:
table initial_loan : loans_span -> currency.
-- initial_loan[l] is the total already borrowed
from loan l at time[1].
Now I define tables analogous to my total_cash tables. These record the progress of each loan over time:
table total_loan_at_start_of_period : loans_span time_span -> currency.
table total_loan_at_end_of_period : loans_span time_span -> currency.
-- total_loan_at_start_of_period[l,t]
is the total lent by loan l at the start of
period t, i.e. the total borrowed from that loan.
Similarly, total_loan_at_end_of_period[l,t]
is the total lent by loan l at the end of
period t.
total_loan_at_start_of_period[ l, 1 ] =
initial_loan[ l ].
total_loan_at_start_of_period[ l, t>1 ] =
total_loan_at_end_of_period[ l, t-1 ].
total_loan_at_end_of_period[ l, t ] =
total_loan_at_start_of_period[ l, t ] + lent_during_period[ l, t ].
The equation for total_loan_at_end_of_period adds in a value for lent_during_period. This is the core of my spreadsheet, for it's here that we record which loan lends during each period, and how much. I'll get on to that later; for the moment, I'll just write up the table:
table lent_during_period : loans_span time_span -> currency.
-- lent_during_period[l,t] is the amount lent by
loan l in period t.
Before explaining how lent_during_period works, I'm going to jump to another part of the calculation. This is where we decide which loans can be borrowed from at any time:
table can_supply_wants : loans_span time_span -> boolean.I like to read this as: can_supply_wants is a table of Boolean (logical) values. The element can_supply_wants[l,t] is true if l has no ceiling, or if the amount the user wants to borrow, plus the amount lent at the start of the period, is less than or equal to l's ceiling.
-- can_supply_wants[l,t] is true if loan l is capable of lending
what the user wants to borrow at period t. This
does not imply that we will in fact use the loan.
can_supply_wants[ l, t ] =
or( not( has_ceiling[l] )
, want_to_borrow_during_period[t] + total_loan_at_start_of_period[l,t] <= ceiling[l]
).
This table tells us which loans the user can borrow from, but how do we decide which they will in fact borrow from? To keep things simple, let's assume it's the first eligible loan, the one with the smallest l.
I am going to arrange can_supply_wants with time running vertically, and l running from left to right with no gaps. With this no-gaps layout, I can find the first "true" by scanning with Excel's "match" function:
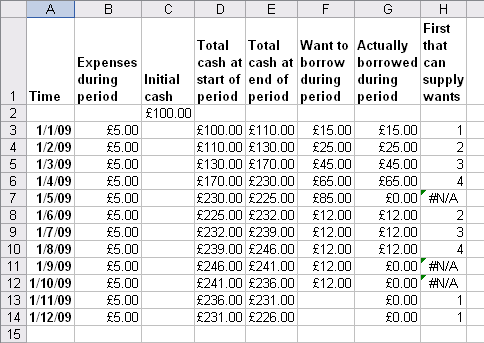
table first_that_can_supply_wants : time_span -> general.Here is a picture of first_that_can_supply_wants, which I've laid out next to the cash tables. If you compare it with the ceilings above, you'll see that the first loan with sufficient funds has been selected each time:
-- first_that_can_supply_wants[l,t] is the first l
for which can_supply_wants[l,t] holds.
It is 1 if the user wants to borrow zero in period t
(this is consistent), and #N/A if can_supply_wants[l,t]
is false for all l, i.e. if no loan can supply what
the user wants.
first_that_can_supply_wants[ t ] =
match( true, can_supply_wants[ all, t ], 0 ).
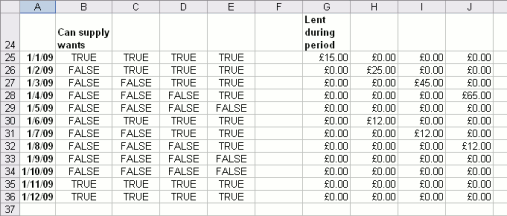
And here is the table that first_that_can_supply_wants
matches against, can_supply_wants, with its
trues and falses. You can also see lent_during_period,
showing the amount each loan has lent, and when:
Let us now return to first_that_can_supply_wants and link it to lent_during_period. I said earlier that lent_during_period[l,t] is the amount lent by loan l in period t. Now I have everything necessary to calculate it:
lent_during_period[ l, t ] =I shall read this as: the amount lent by loan l in period t is 0 if first_that_can_supply_wants[t] is #N/A: that is, if the match found no trues. Otherwise, if first_that_can_supply_wants[t] is l, it is the amount the user wants to borrow. Otherwise it is 0.
if( isna( first_that_can_supply_wants[t] )
, 0
, if( l = first_that_can_supply_wants[ t ]
, want_to_borrow_during_period[ t ]
, 0
)
).
Ich am eldre and ek magti! At last, I can define actually_borrowed_during_period:
actually_borrowed_during_period[ t ] =This is just the sum over all loans of the amount lent during period t. In the pseudo-code, I've used the subscript "all" to indicate that the sum ranges over the entire first dimension of lent_during_period.
sum( lent_during_period[ all, t ] ).
And now, having finished the documentation, I build the spreadsheet by deciding where to put my tables, and then translating the equations into Excel formulae. (I know I showed pictures of it above, but that's because I went back over this posting and inserted them once I'd built it.) It is here. But the crucial point is that I now have a nice formal description of the spreadsheet, with every cell group documented. (In this posting, you'll get it by collecting all the indented pseudo-code fragments.)
By the way, this posting is the third in a series about documenting spreadsheets. It follows from Gliders, Hasslers, and the Toadsucker: Writing and Explaining a Structured Excel Life Game and How to Document a Spreadsheet: an Exercise with Cash-Flow and Loans. In these, I used my spreadsheet-description language Excelsior to show how to document first, then write an Excelsior program around the documentation, and then translate this into Excel. But Excelsior isn't essential; and in this posting, I am treating the Excelsior program as pseudo-code. Its benefit is that it gives you a precise design which you can work out on paper before ever touching Excel. Which is good, because to change a design in Excel, you may need to erase ten tables and a thousand cells, then retype, re-fill, and re-fill yet again. To change a design on paper, you need only a rubber.