Here, the task is one of working out which suffix - s, ed, ...- to stick onto a root. In generating irregular forms, the information we needed was held in the lexicon. For regular forms, it is held elsewhere, in the word-grammar rules. Explaining this requires a bit more knowledge about the MA.
I haven't checked in detail, but I believe the MA works in the following
fashion. When asked to analyse a word, the MA first segments it into all
possible combinations of morphemes, by moving along the word and looking
up every possible substring in the lexicon. From these, it builds up all
the possible sequences of lexical entries whose citation fields can be
concatenated to form the original word. This is illustrated below: the
function that does the segmentation is externally callable under the
name D-Segment. The lexicon used in this example had two entries
for throughout, one for through, and four for out.
> (D-Segment "throughout")
(
(("throughout" |throughout|
((FIX NOT) (INFL +) (BAR |0|) (N -) (V -) (PFORM NORM) (PRD +)
(SUBCAT NP) (PRO -) (CONJ NULL) (AT +) (LAT +) (COMPOUND NOT))
"throughout" NIL))
(("throughout" |throughout|
((FIX NOT) (INFL +) (BAR |0|) (V -) (N -) (SUBCAT NP) (PRO -)
(CONJ NULL) (AT +) (LAT +) (COMPOUND NOT) (PFORM THROUGHOUT))
"throughout" NIL))
(("through" |through| ((FIX NOT) (PRT THROUGH)) "through" NIL)
("out" |out| ((FIX NOT) (PRT OUT)) "out" NIL))
(("through" |through| ((FIX NOT) (PRT THROUGH)) "through" NIL)
("out" |out|
((FIX NOT) (INFL +) (BAR |0|) (N -) (V -) (PFORM NORM) (PRD +)
(PRO -) (CONJ NULL) (AT +) (LAT +) (COMPOUND NOT) (SUBCAT PP))
"out" NIL))
(("through" |through| ((FIX NOT) (PRT THROUGH)) "through" NIL)
("out" |out|
((FIX NOT) (INFL +) (BAR |0|) (N -) (V -) (PFORM NORM) (PRD +)
(SUBCAT NP) (PRO -) (CONJ NULL) (AT +) (LAT +) (COMPOUND NOT))
"out" NIL))
(("through" |through| ((FIX NOT) (PRT THROUGH)) "through" NIL)
("out" |out|
((FIX NOT) (INFL +) (BAR |0|) (V -) (N -) (SUBCAT NP) (PRO -)
(CONJ NULL) (AT +) (LAT +) (COMPOUND NOT) (PFORM OUT))
"out" NIL))
(("through" |through| ((FIX NOT) (PRT THROUGH)) "through" NIL)
("out-" |out-|
((INFL +) (BAR |-1|) (FIX PRE) (STEM ((N -) (V +) (BAR |0|))))
"out-" NIL))
)
Abstractly, this implements a function 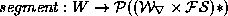 which maps a string to a set of sequences of
citation-form/feature-set pairs. Each of these sequences will,
if all its elements are joined, give back the original word. The only
elements that can appear in these sequences are the citation forms in
the lexicon. Within that constraint, all possible sequences are
generated.
which maps a string to a set of sequences of
citation-form/feature-set pairs. Each of these sequences will,
if all its elements are joined, give back the original word. The only
elements that can appear in these sequences are the citation forms in
the lexicon. Within that constraint, all possible sequences are
generated.
Note that this has implications for the lexicon-writer. If the lexicon contains the compound word superman, and also the morphemes super and man, then morphemic segmentation of superman will find the two simple morphemes as well as the compound word. Putting a compound into the lexicon does not override segmentation into smaller units.
The next step is to check which of these sequences are grammatically
valid. 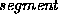 does not do this, and will, for example, happily
segment a word into a noun root plus a verb past-tense suffix, as
section 4.2 of [MA] implies. Such checking is done by the
word-grammar rules. These can be thought of as implementing a filter
function:
does not do this, and will, for example, happily
segment a word into a noun root plus a verb past-tense suffix, as
section 4.2 of [MA] implies. Such checking is done by the
word-grammar rules. These can be thought of as implementing a filter
function: 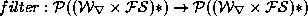 . This process does not generate any new morphemes,
so the result of
. This process does not generate any new morphemes,
so the result of 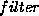 is a subset of its argument.
is a subset of its argument.
In fact, the word-grammar rules don't just filter out inappropriate
segmentations, they also generate feature-structures to describe the
appropriate ones. So we need to replace by 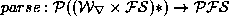 . The combination of and
. The combination of and
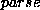 is what
is what D-LookUp implements. The end of section 7.8 of
[G+M] describes a language analyser that works along very similar
lines.
Collectively, the word-grammar rules specify which feature-sets can occur in combination, and hence which of a word's segmentations are valid. They also enable the parser to construct one feature-set which describes the whole sequence.
Here is the source form of a sample word-grammar rule: one similar, but not identical, to one of those supplied with the Alvey lexicon:
( N-PLURAL
[BAR 0, PLU +, V -, N +] ->
[BAR 0, PLU -, V +, N -],
[FIX SUF, PLU +, V -, N +]
)
The N-PLURAL is the name of the rule, and is not used by the
parser. The things in square brackets here are feature-sets, written in
the notation I used in the introduction. List notation is also
acceptable, as are various abbreviations. All these are explained in
section 7 of [MA]. If all the feature-sets were written as lists,
this rule would become
( N-PLURAL
( (BAR 0) (PLU +) (V -) (N +) ) ->
( (BAR 0) (PLU -) (V +) (N -) ),
( (FIX SUF) (PLU +) (V -) (N +) )
)
This is worth mentioning, because it is similar, though not identical,
to the way the rules are represented internally: see
section 3.3.3.
The meaning of the rule to the parser is merely that if two morphemes occur, one with the feature-set
[BAR 0, PLU -, V +, N -]and the following one with the feature-set
[FIX SUF, PLU +, V -, N +]that combination is allowed. The set describing the whole sequence is
[ BAR 0, PLU +, V -, N +]This rule could be used to describe noun plurals. As I mentioned in the introduction, lexical nouns are represented by the feature combination
[V -, N +, BAR 0], rather than by one feature such as [CAT
NOUN]. The plural suffix s has a lexical entry which includes the
features [FIX SUF, PLU +, V -, N +]. So the rule is saying ``if
you find a singular noun-morpheme, and a plural suffix, the combination
is allowed, and counts as a plural noun''.
At first sight, I thought it would be easy to generate regular
forms by running the rules backwards. Suppose we have a feature-set 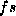 which describes a plural noun, and we have a root
which describes a plural noun, and we have a root  , in the sense of
section 3.2.5 on irregular forms. We also have a set of
word-grammar rules, one of which is the noun-plural one above:
, in the sense of
section 3.2.5 on irregular forms. We also have a set of
word-grammar rules, one of which is the noun-plural one above:
[BAR 0, PLU +, V -, N +] ->
[BAR 0, PLU -, V +, N -],
[FIX SUF, PLU +, V -, N +]
Then we could proceed as follows. First, match against the
left-hand side of each rule. It should certainly match the left-hand
side of the noun-plural one, and we hope it won't match any of the
others.
Next, look at the two feature-sets on the right-hand side. Do either of them describe lexical entries? If so, then we can pick these from the lexicon. If not, we will have to match these new feature sets against the rules, repeating the process recursively until all our sets map onto the lexicon.
In this case, the first set on the right-hand side is that for a
singular noun. Suppose our root were abbot. Then we could
find a lexical entry for abbot as a singular noun, so we have one
morpheme. The second set on the right-hand side is that for the
plural morpheme. It is marked as an affix, rather than a morpheme which
can stand on its own, by the feature FIX SUF. Scanning the
lexicon, we find only one entry whose features are
[FIX SUF, PLU +, V -, N +]This is the suffix s, so we know it's the one we want. We therefore end up with the two morphemes abbot and s.
Before being able to manipulate rules in this way, we need to know how they're stored. This section goes into a bit of detail about the internal workings of the relevant MA code. Useful to the software archeologist, but skimmable by others.
Like lexica, word-grammar rules have to be ``compiled''
before they can be used. This is done by calling the routine
D-MakeWordGrammar with a filename as argument. It reads the
rules' source text from <file>-gr and writes a compiled form to
<file>-gr.ma. Compiled word-grammars must be loaded with the
routine D-LoadWordGrammar.
The compiled-rules file consists of a number of Lisp S-expressions. They
are not documented in the MA code, but I have worked out some of what
they are for by reading the module that loads word-grammars,
SMAFUNCS.LSP and the one that compiles them, SMKWGRAM.LSP,
and by dumping sample files. As with compiled lexica, the compiled rules
are much easier to read if you compile them with the
*print-pretty* flag on.
The most important S-expression is the second one in the file. This is a list of lists. When I compile the rules that come with our lexicon, it looks like this:
(
(T COMPOUNDS-N
((COMPOUND N) (N +) (V -))
((N +) (V -) (INFL +) (FIX NOT) (NUM -) (COMPOUND |?yorn|) (PN -))
((N +) (V -) (COMPOUND NOT) (NUM -) (INFL +) (FIX NOT) (PN -)))
(T V-SUFFIXES7
((BAR |0|) (V +) (N -))
((BAR |0|) (V +) (N -) (SUBTYPE |?st2|))
((FIX SUF) (PSVE -) (AFFREG ODD1) (V +) (N -)))
... <etc> ...
(T PREFIXES
((BAR |0|) (N |?bool1|) (V |?bool2|)) ((FIX PRE))
((BAR |0|) (N |?bool1|) (V |?bool2|)))
)
On calling D-LoadWordGrammar, it is assigned to the global
variable D-GRAMMAR. Each element is the compiled form of one
rule: the rules are stored in reverse order.
Each compiled rule is a list with the form
(<?> <name> <lhs> <rhs1> <rhs2> ... )I am not sure what the first entry is, but it may indicate whether the rule contains any feature variables. The second is the rule's name, and the following ones are the feature-sets. These are lists of lists, each inner list being a feature-value pair in the form
(<feature> <value>)
Feature values appear to be either symbols (for ground values) or lists (for feature-variables). I think they can also be feature-sets, but none of the rules in the MA lexicon have this. Variables are stored in the form
(<integer> <value1> <value2> ... )as described in section 3.2.8.
Other S-expressions in the file carry things like the contents of the
WHead and Alias declarations. Looking at the names of the
global variables printed by the print statements in
D-MakeWordGrammar in SMKWGRAM.LSP will indicate where
these come in the file.
Although the internal form of rules is easy to handle, I have found a few other problems with the idea of running rules backwards. These I list below. The final two are the most serious, and are dealt with in more detail in the following section.
N-PL, the
first feature-set on the right-hand side required us to find the correct
lexical entry for a given root. However, in the second one, the root was
irrelevant, and we had to search the lexicon for the one and only affix
with a given feature set. How do we distinguish between these cases, and
how do we implement an efficient affix search?
The natural way for someone writing a Dutch lexicon to deal with this
would be to have two lexical entries, one for en and one for s, both with the feature-set [FIX SUF, PLU +, V -, N +].
However, though this is no problem for the analyser, it would mean that
on generation, we would not have enough information to choose which
plural suffix to add.
![]()
Since we are not concerned with foreign languages, this doesn't affect
the Assistant directly.
![]() It was worth mentioning though since something like this could have
happened in English. I can't think of any examples, and none of the
inflectional affixes in the lexicon behave in this way.
It was worth mentioning though since something like this could have
happened in English. I can't think of any examples, and none of the
inflectional affixes in the lexicon behave in this way.
English has a large variety of affixes. Prefix affixes include dis, non and super; suffix affixes include ation, ed, ess, est, hood, ly and s.
Linguistics (or at least the references I have checked on) makes a distinction between two types of affix, inflectional and derivational. Inflectional affixes can be applied to any word of a given part of speech, and change its meaning in a uniform way. Thus, the plural suffix s can be applied to any noun; given the meaning of the singular, you know that of the plural. The same goes for the past-tense inflection ed. (Irregular words have to be treated specially here, but there is still usually some way to inflect them.) In general, inflectional affixes do not change a word's part of speech: abbot and abbots are both nouns; read, reads and reading are all verbs; great, greater and greatest are all adjectives. (I am not sure how ing, as in he finished the editing fits in here.)
Derivational affixes cannot be applied with the same uniformity. It is permissible to say disconnect but not (*) disblow; to say motherhood but not (*) mousehood; to say quickly but not (*) yellowly. When they can be applied, the change in meaning is less predictable: compare bespectacled with beheaded. Some derivational affixes do change the part of speech, as in edit to editor.
I am not sure how much the inflectional/derivational distinction is
universally applicable over the world's languages. However, from the
viewpoint of the MA and its English lexicon, the distinction reflects
the information available about the affixes. The meaning of derivational
affixes is not captured in the feature sets generated from the
word-grammar rules. That of inflectional affixes is. So the feature set
for mothers has a feature marking it as plural; but that for motherhood does not contain any information about the meaning of hood. In fact, the feature sets which D-LookUp generates for
mother and motherhood are identical.
This causes problems. In section 3.3.1, I showed a word-grammar rule for noun plurals. In fact the MA lexicon does not include a rule that's specific to these. Instead, there's one general rule for all noun suffixes:
( N-SUFFIXES
[BAR 0, N +, V -] ->
[BAR 0, N ?bool1, V ?bool2],
[FIX SUF, N +, V -] )
The [FIX SUF, N +, V -] feature-set will match any suffix which
has these features in its lexical entry. As the lexicon is written, this
means any suffix which converts the word to which it's appended into a
noun. (The things beginning with ? are feature variables, which
don't concern us here.)
This includes the plural suffix s, whose feature-set is [FIX
SUF, PLU +, V -, N +]. But how does the parser know that if it has
found a plural suffix, it should transfer the feature-value pair
PLU + to the left-hand side of the rule? There is nothing in the
rule above to tell it so.
The answer is the ``word head'' convention, described in section 7.9 of [MA]. This is one of several means provided by the MA to reduce the amount of explicit information that the person writing the rules needs to put down. The word-head convention applies only to rules of the form
mother -> daughter1 daughter2It stipulates that if the parser can match against such a rule, then the values of any features declared in a
FeatureClass WHead
declaration will be the same in the right daughter as in the mother.
Thus, if the rules-file contains the declaration
FeatureClass WHead = {PLU, POSS}
then if the parser matches this rule against a suffix with the PLU
+ or POSS 1 features (say), then the feature-set
resulting from the whole rule will also be given them. Roughly speaking,
the parser appears to achieve this by filtering out from the suffix's
feature-set those features which appear in the WHead declaration,
and unifying them with the left-hand side of the rule.
There are several other feature-passing conventions, all described in section 7.9 of [MA]. Briefly, these are
WDaughter declaration. If one of these
appears in the right daugheter, the mother must have the same value;
otherwise, the mother must have the same value as in the left daughter.
LCategory statement for the feature PLU would cause every
feature-set generated by the parser to have a PLU feature. If its
value isn't set in any other way, it will be given a special ``don't
care'' value starting with the @ character.
STEM feature, it should have a feature-set as its
value. The feature-set of the other daughter must then be compatible
(technically, an extension of) with this. This is different from the
other conventions since it doesn't add to the feature-set generated by
parsing, it just restricts the number of possible parses.
The points introduced in this section have the following consequences:
lhs -> stem suffixFurthermore (I think), no English word can carry more than one inflection. If we are prepared to sacrifice linguistic generality, we could therefore ``pre-compile'' these rules into a look-up table which takes a feature-structure and returns the appropriate affix. This is likely to be simpler than running them backwards by interpreting them.
N-SUFFIXES above really corresponds to many different rule
``instances'', each of which attaches a different suffix, and each of
which has a different left-hand side. To build our lookup table, we
need to construct each of these instances.
In the following section, I talk about how we preserve roots and
derivational affixes. This includes a description of the format of
D-LookUp parse trees. The section after that,
section 3.3.7 discusses the problem of reversing the
inflectional rules.
To recap, the idea behind morphological generation is that the Assistant
will request a feature-set by calling D-LookUp on some word, abbot for example. It may later decide on the basis of various
syntax-checking rules that some features have the wrong value, e.g. that
the noun should have been pluralised. If so, it will try and generate
replacement text for the word, by passing the amended feature-set back
to the generator.
The question arises of where the generator is going to get the root
morpheme for abbot from, onto which it affixes the plural s.
By default, D-LookUp only returns a set of feature-sets, each
reflecting one possible analysis of the word. None of these contain the
root morpheme.
It is, however, possible to change the ``lookup format'' by calling
D-ChangeLookUpFormat, as described in [MA] sections 3.1 and
3.2. If it is changed to 'D-WORDSTRUCTURE, D-LookUp will
return a parse-tree, giving all rules and lexical entries entering into
the word's successful parses. This does contain the root morpheme as
part of an embedded lexical entry, but one has to know the tree's
structure in order to find it.
Now suppose we look up superabbot. Assuming there is no lexical
entry for this, but that there are entries for super and abbot, the MA will first do a morpheme segmentation and
find that the word
can be decomposed into these two morphemes, and will then call the
word-grammar rules to check that they are syntactically correct in
combination. If the lookup-format is 'D-WORDSTRUCTURE, it will
again return a parse tree, this time containing the two morpheme entries
as leaves. This leads to the idea that we can pick off the leaves of
these parse trees, and hence build a list of root morphemes.
That in essence is what I do in the auxiliary routine
EA-ParseTreeToSkeleton, taking a parse tree and returning a list
of root morphemes, which I call a ``skeleton''. For the noun superabbothood, the skeleton would be
("super-" "abbot" "+hood").
The skeleton includes derivational affixes, but not inflectional ones.
When building a skeleton,
EA-ParseTreeToSkeleton needs to distinguish the two. There are
two ways it could do this: by examining the rules, or by examining the
suffixes. The first would require some way of distinguishing
inflectional rules from derivational ones. With the existing grammar,
this is not possible since one rule can be used for both purposes.
However, it is possible to rewrite the rules so that there are separate
inflectional ones, and I have tried this. I also added a new declaration
Inflectional which was followed by the names of all the
inflectional rules, and which was ``compiled'' into a list of these
names. With this, it was possible to implement
EA-ParseTreeToSkeleton.
This method, or a modification thereof, would have been useful if I had
decided to run the rules backwards during generation. Since eventually I
didn't, it seemed better to leave them alone and have
EA-ParseTreeToSkeleton examine the suffixes instead. (I suspect
that factoring out one rule into several leads to parsing inefficiency.)
In my test lexicon, I therefore marked all the inflectional suffixes
with a GENINFL + feature, and added a completion rule so that all
the others got a GENINFL - feature. This rule, below, had to be
added to my version of the dru file which gets included by the
lexicon source text:
Add_GENINFL_MINUS:
(_ _ ((FIX SUF) ~(GENINFL _) _rest) _ _) =>
(& & ((FIX SUF) (GENINFL -) _rest) & &)
It was also necessary to add a Feature GENINFL{+, -} declaration
to the file decls. This is a set of feature declarations that
gets included in the lexicon and the word-grammar rules.
Given these markers, it is easy to convert parse trees into skeletons. A
skeleton is a list of citation forms, and is used by the main
morphological generation routine, EA-CatAndSkeletonToWords. This
takes a skeleton and a feature-set, and inflects the rightmost
morpheme in the skeleton, either adding an inflectional suffix or
replacing by an irregular form.
A typical lookup-and-regenerate sequence will then go something like this:
(D-ChangeLookUpFormat 'D-WORDSTRUCTURE) (setq parse-tree (D-LookUp word)) (setq skeleton (EA-ParseTreeToSkeleton parse-tree)) (setq feature-set (EA-ParseTreeToCat parse-tree)) ... possibly change some features in feature-set ... (setq new-words (EA-CatAndSkeletonToWords feature-set skeleton))Here,
EA-ParseTreeToCat is a utility for extracting the
feature-set from a parse-tree, to save the caller having to know how to
do this.
The use of skeletons relies on the assumption that if you you need to make any inflectional changes, you inflect only the right-hand morpheme. That is, apparently, always valid for simple words in English. It is usually valid for compounds too: piggy-back/piggy-backed. There are a few exceptions like mother-in-law/mothers-in-law. These are best treated as special lexical entries with irregular plurals. Doing so would also stop the MA from accepting (*) mother-in-laws as a plural, which it may do now (I haven't checked).
I end with an account of how parse trees are represented. This is described in full in section 3.2 of [MA], and also in section 7.7. The former describes how the tree is represented as a list; the latter, how the feature structures in its nodes are related by unification to those in the lexicon and word-grammar rules.
D-LookUp returns, when in 'D-WORDSTRUCTURE mode, a list of
trees, each corresponding to one of the successful parses. Each tree has
the form
( <feature-structure> 'ENTRY <lexical entry> )or
( <feature-structure> <rule name> <subtree1>* )
The first type of tree is that for a lexical entry, where no rules were
involved. The second element is the symbol ENTRY, and the third
element is the lexical entry itself. Use the second element to
distinguish between this kind of tree and that which represents the
application of a rule. Note: it is probably not a good idea to name a
word-grammar rule ENTRY!
The second type of tree represents the application of a rule. Its second element is the rule's name. The elements following are themselves trees, corresponding to the feature structures in the rule's right-hand side.
I have already discussed some of the problems with this. I think the most workable approach is to pre-compile the rules into a mapping from feature-sets to suffixes, as follows:
lhs -> stem suffixWe now need to generate one ``instance'' of this for each possible suffix. The left-hand side of each instance will have all its features fully specified, none being left implicit in word-head or other conventions. The objective is to end up with a list of instances of the form
lhs -> suffixGiven a feature-set to generate from, we then match it against each left-hand side in turn. If it matches more than one, this is an error; if it matches none, that may be an error; if it matches only one, we return the corresponding suffix.
suffix feature-set to that for each suffix in turn.
One way to do this would be to fool the parser. Suppose that the
lexicon contained a copy of the entry for each inflectional suffix, with
the citation field zzzz. Suppose also that it contained a copy of
the entry for each stem, with the citation field aaaa. Then if we
did a D-LookUp on the ``word'' aaaazzzz, we would get a
list of all the possible parse trees. These would contain the
feature-sets resulting from each parse, including all the features
constructed by the feature-passing conventions. We could use these as
the left-hand sides of our rules, and the real lexical entry for each
suffix as our right-hand side. I haven't thought this through, but such
a method would avoid having to use all the feature-passing information.
Although I think this is possible, it would have meant quite a lot of poking around inside the MA, and probably some wasted time while I found out how various internal routines and data-structures worked. It seemed more sensible to - at least for a first trial - to abandon this approach and have the grammar-writer write a separate set of generation rules instead. All we need is a a list of feature-set/suffix pairs. These would be easy to compile, and easy to generate from, by comparing a feature-set with each pair in turn until a match was found. In addition, they make it explicit exactly which features are used to distinguish one suffix from another. Implicitly generated rules would not do this, and in that sense, are worse software engineering. Finally, English has very few inflections, so the time taken to write and debug the generation rules should be much less, even including their implementation, than that taken to implement a general rule-reverser. (We are only concerned with English in this version of the Assistant.)
I have therefore modified the word-grammar compiler in
SMKWGRAM.LSP so that it accepts ``generational rules''. These
are declared as an optional final section in the word-grammar file,
headed by the word Generation. Each rule has the form
( <name> <lhs> -> <affix> )where
<name> is the same kind of thing as the name of the analysis
rules, <lhs> is a feature-set, and <affix> is a string.
<affix> is written in the lexical alphabet, not the surface one,
and should therefore be something that the spelling rules
(section 3.4) can sensibly be run backwards on. Usually,
it will be the same as one of the citation forms in the lexicon. The
only features that will appear in the compiled form of the left-hand
side are those put in by the author; I do not add any defaults.
As an example, these are the rules that I am currently using at the end
of my modified d-gr file:
Generation
; Noun plural.
( N-PLURAL
[ BAR 0, N +, V -, PLU + ] -> "+s" )
; Adjective comparatives.
( A-ER
[ BAR 0, N +, V +, AFORM ER ] -> "+er" )
( A-EST
[ BAR 0, N +, V +, AFORM EST ] -> "+est" )
; Verb -ing.
( V-ING
[BAR 0, V +, N -, VFORM ING] -> "+ing" )
; Verb past tense.
( V-PAST
[BAR 0, V +, N -, FIN +, PAST +] -> "+ed" )
; Verb past participle.
( V-PAST-PART
[BAR 0, V +, N -, VFORM EN] -> "+ed" )
; Verb passive.
( V-PASSIVE
[BAR 0, V +, N -, PSVE +] -> "+ed" )
; Verb 3rd present singular.
( V-3PS
[BAR 0, V +, N -, FIN +, PAST -] -> "+s" )
English being as inflectionally simple as it is, these cover (I
think) all the regular inflectional affixes. With the standard MA
lexicon, you can probably use them almost as they are, though I would
like a linguist familiar with the MA to check them.
These rules are compiled by code in SMKWGRAM.LSP, and loaded by
code in SMAFUNCS.LSP. The latter assigns them to the global
variable EA-GENERATION-RULES, where they are stored as a list of
lists, each inner list having the form
( <name> <feature-set> <affix> )
They are used by the routine EA-CatToAffix in
MORPHGEN.LSP. This is described in the comments there. Put
briefly, it unifies its feature-set argument with each left-hand side in
turn. If more than one left-hand side successfully unifies (i.e. more
than one rule matches), it will raise an error. Otherwise, it returns
the corresponding affix.
To compile the word-grammar rules, call D-MakeWordGrammar as
usual. To load them, call D-LoadWordGrammar, again as usual. I
have modified the rest of the MA so that these routines deal
automatically with the generation rules. If you are not interested in
generation, you can omit the generation rules and everything will work
as before.
Note: the word-grammar file which I added these rules to had a final
declaration section called Semantics. This is recognised by the
code of the MA, but is not described in [MA].